|
I am a Postdoctoral Researcher at The Chinese University of Hong Kong, working with Prof. Yu Cheng, and a Researcher at Shanghai AI Laboratory. My research focuses on scalable reasoning and alignment for large language models, spanning reinforcement learning with verifiable rewards (RLVR), off-policy training, inference-time optimization, and rigorous evaluation.
Email / Google Scholar / Twitter / Github |

|
|
My research focuses on reasoning, trustworthy AI and multilinguality. *: equal contributions. †: project lead or corresponding author. |
|
|
|
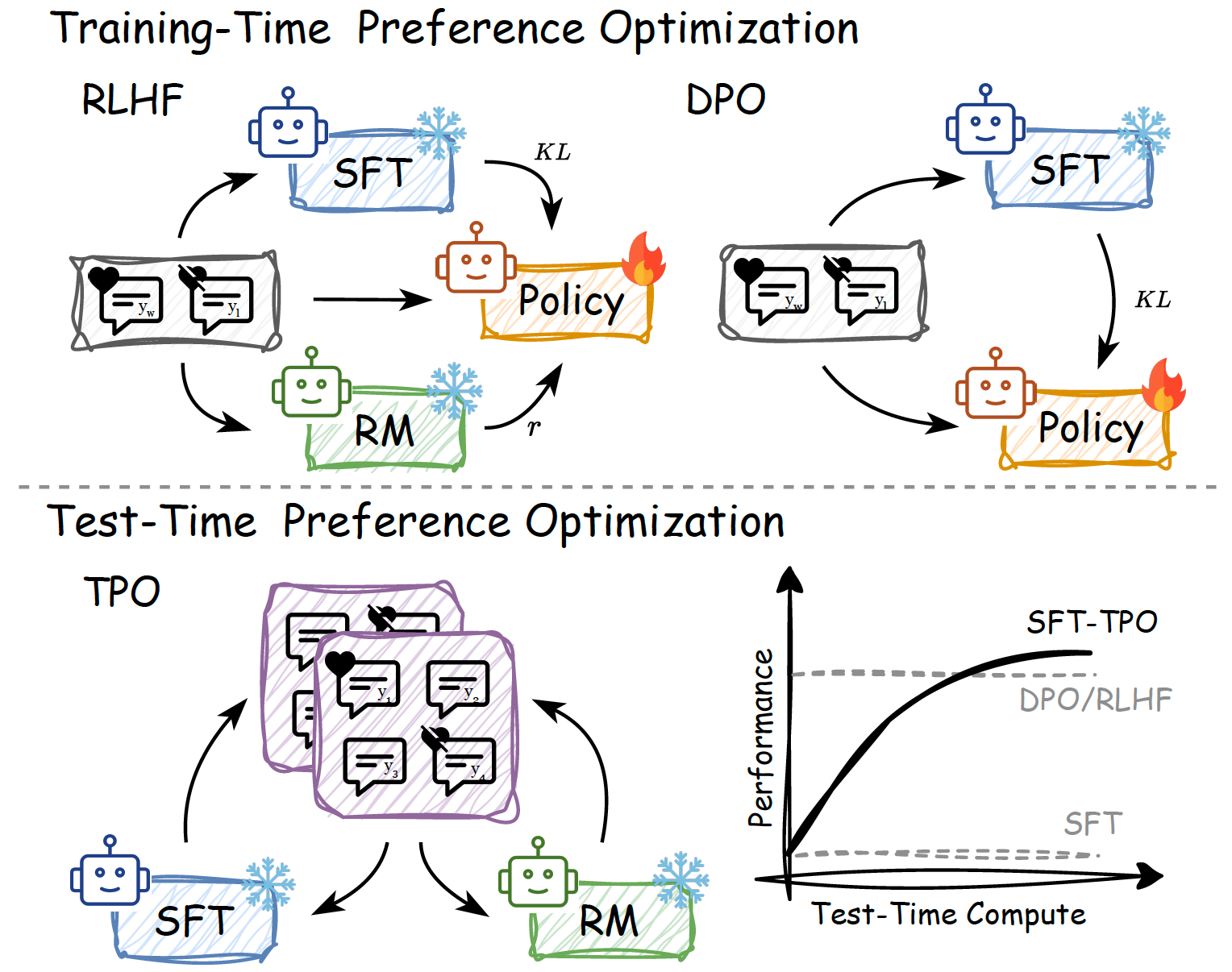
Yafu Li, Xuyang Hu, Xiaoye Qu, Linjie Li, Yu Cheng ICML, 2025 Github / Paper Aligning LLMs at test time via textual reward. |
|
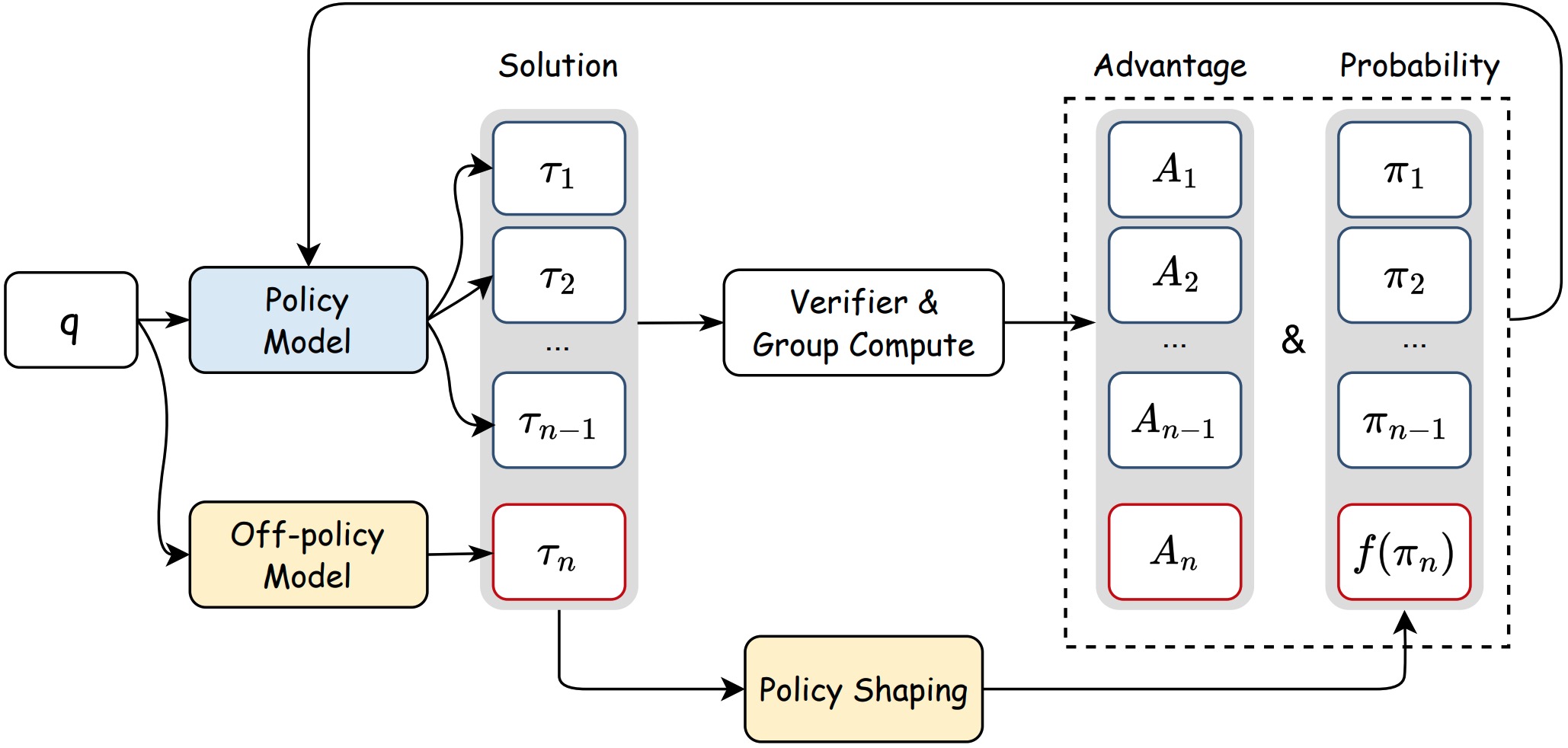
Jianhao Yan*, Yafu Li*†, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, Yue Zhang NeurIPS, 2025 Github / Paper Boosting reasoning performance using off-policy guidance. |
|
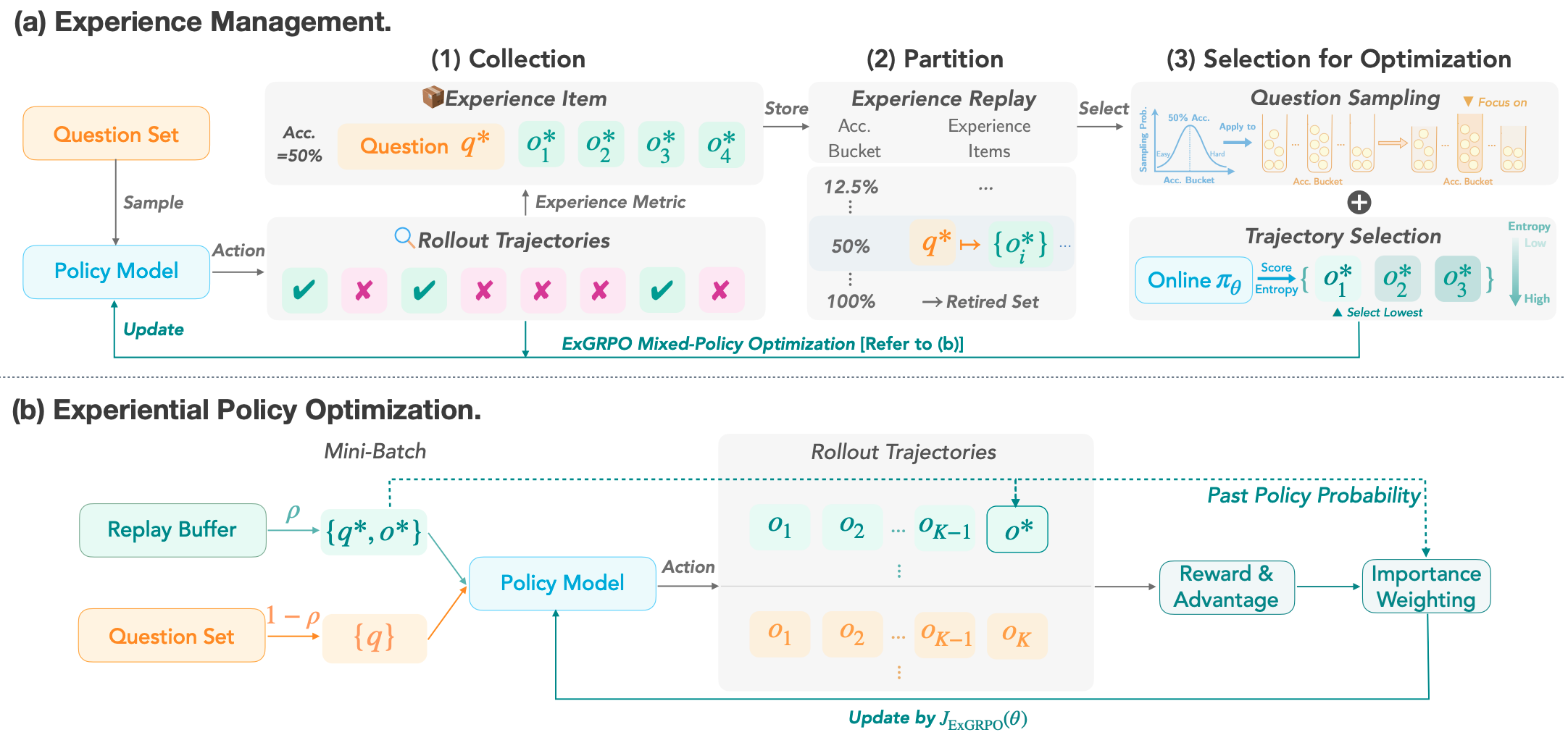
Runzhe Zhan, Yafu Li†, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F. Wong, Yu Cheng ICLR, 2026 Github / Paper Boosting reasoning performance with the model's own experience. |
|
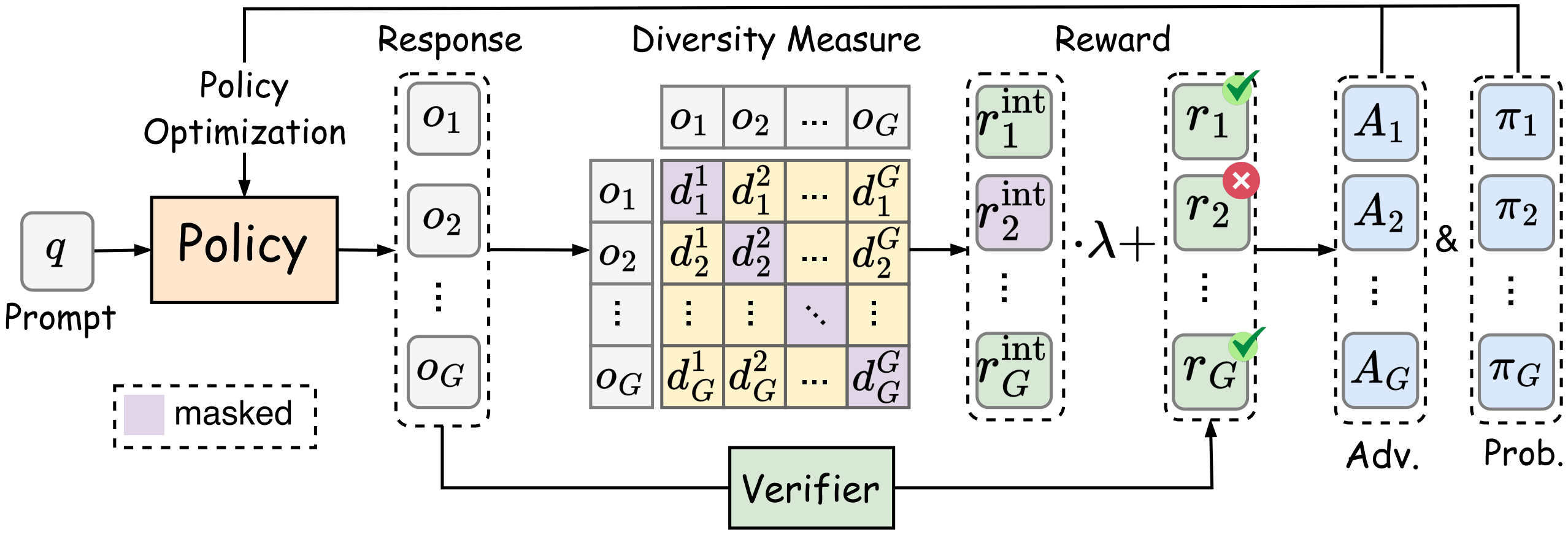
Zican Hu, Shilin Zhang, Yafu Li†, Jianhao Yan, Xuyang Hu, Leyang Cui, Xiaoye Qu, Chunlin Chen, Yu Cheng, Zhi Wang ICLR, 2026 Github / Paper Encouraging global exploration. |
|
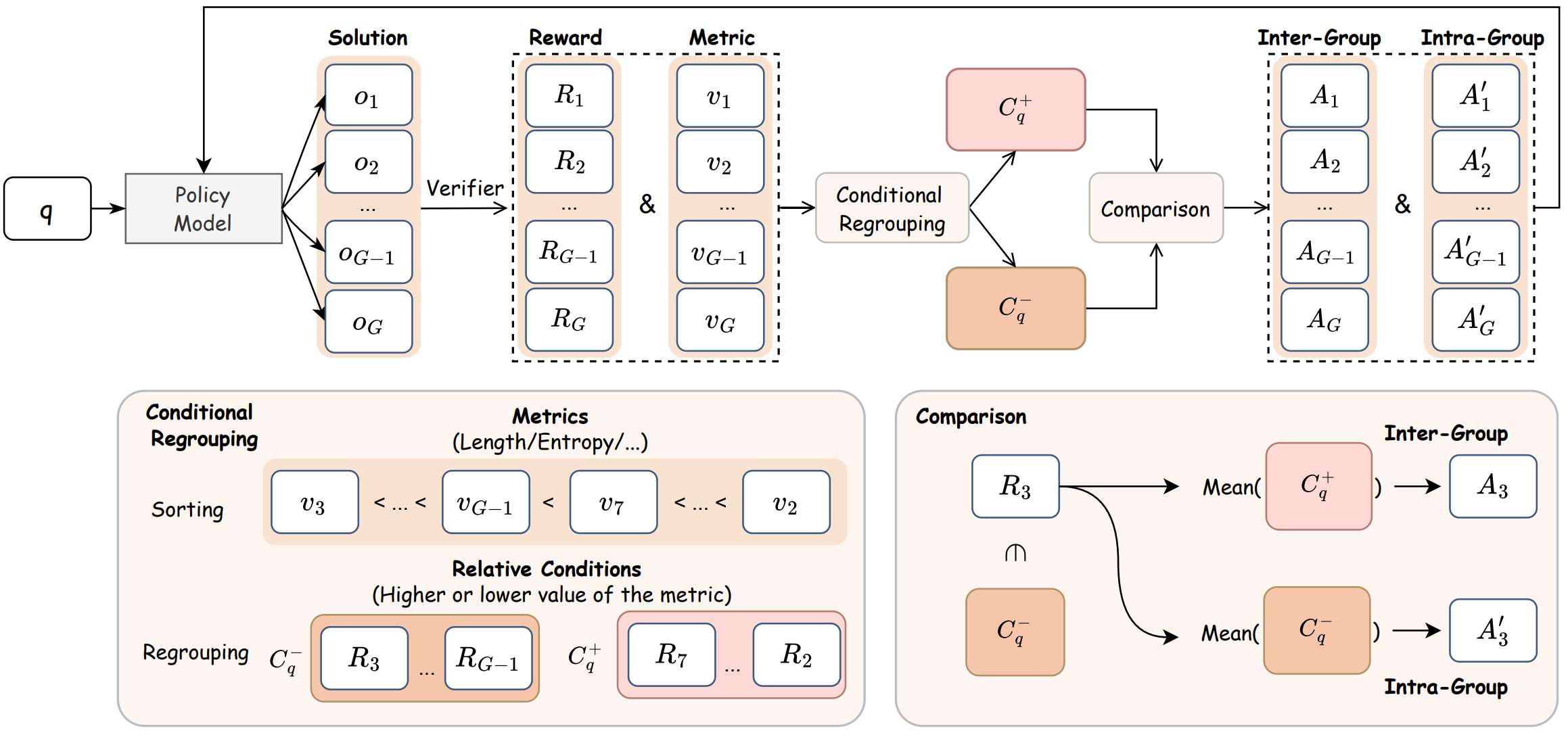
Guanxu Chen, Yafu Li†, Yuxian Jiang, Chen Qian, Qihan Ren, Jingyi Yang, Yu Cheng, Dongrui Liu, Jing Shao ICLR, 2026 Github / Paper Digging implicit signals via group comparison. |
|
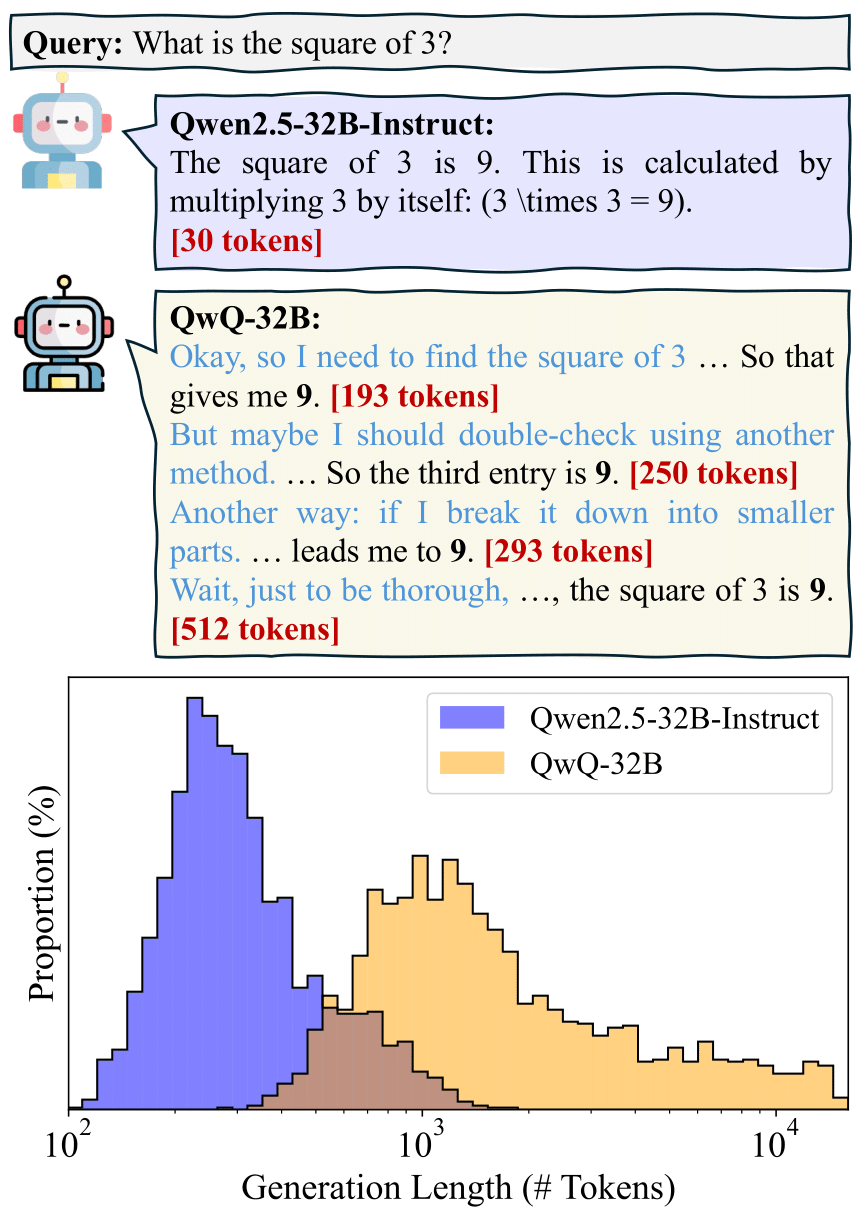
Xiaoye Qu*†, Yafu Li*†, Zhaochen Su, Weigao Sun, Jianhao Yan, Dongrui Liu, Ganqu Cui, Daizong Liu, Shuxian Liang, Junxian He, Peng Li, Wei Wei, Jing Shao, Chaochao Lu, Yue Zhang, Xian-Sheng Hua, Bowen Zhou, Yu Cheng preprint Github / Paper A survey of efficient reasoning for Large Reasoning Models. |
|
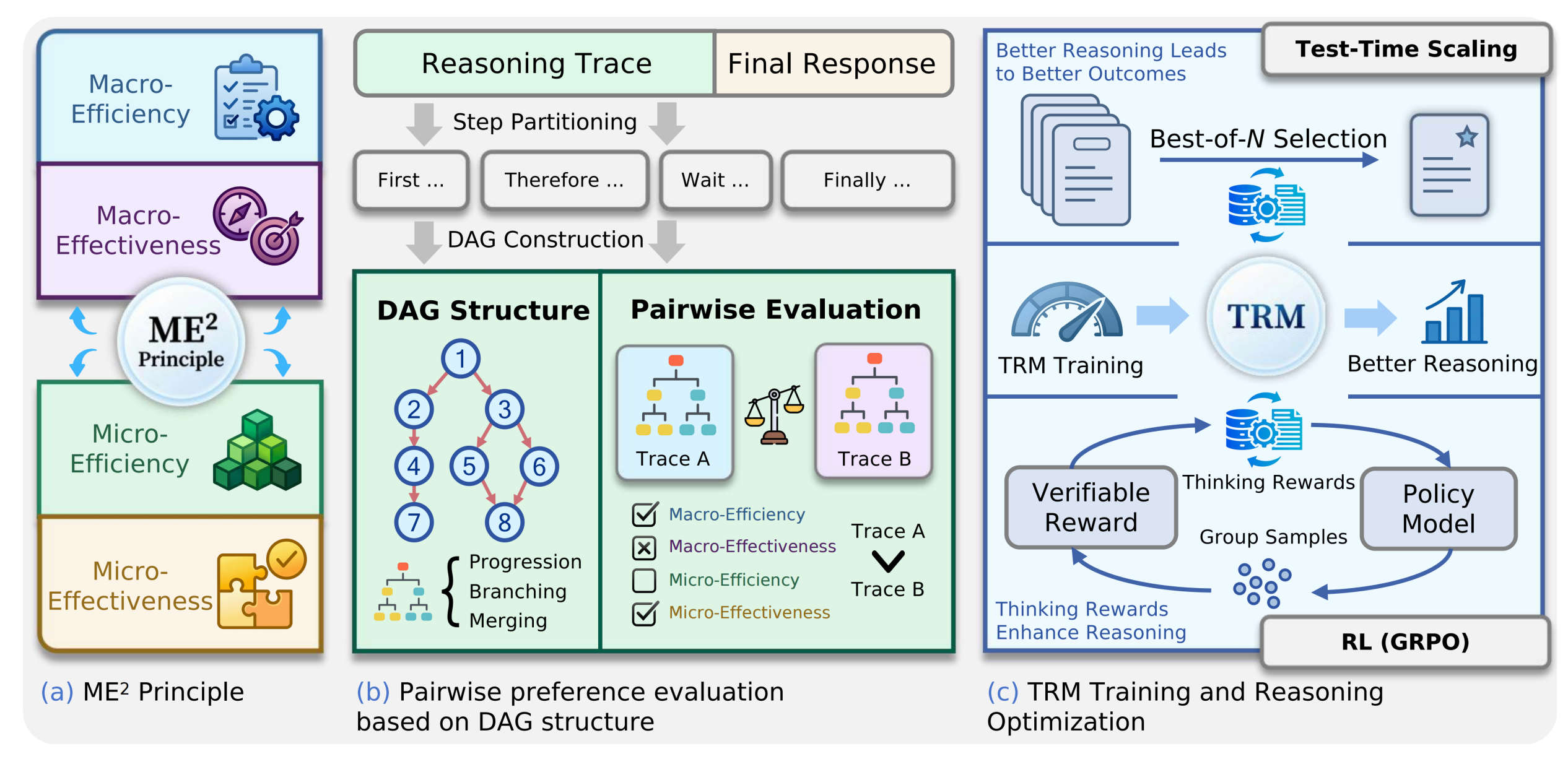
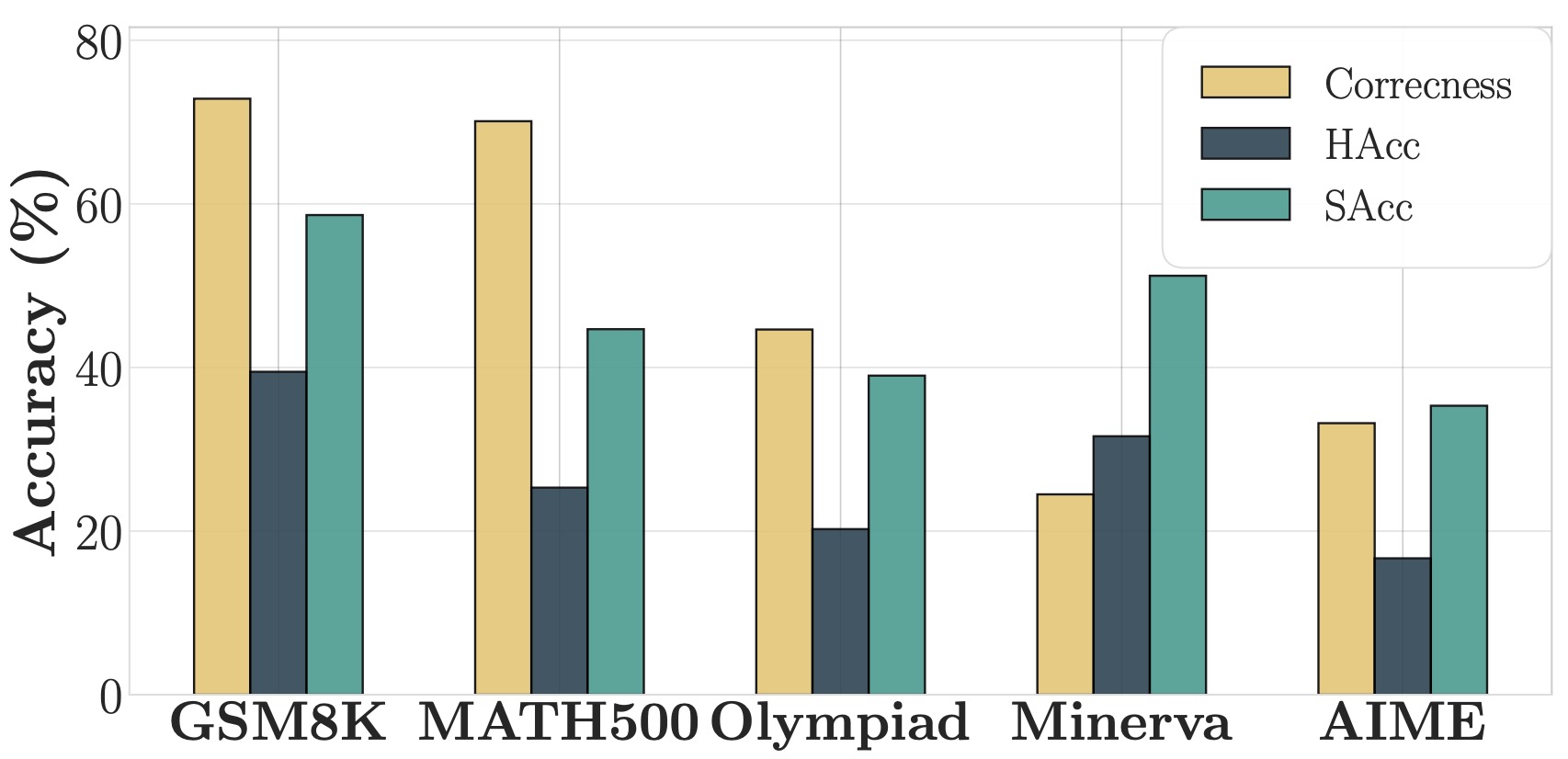
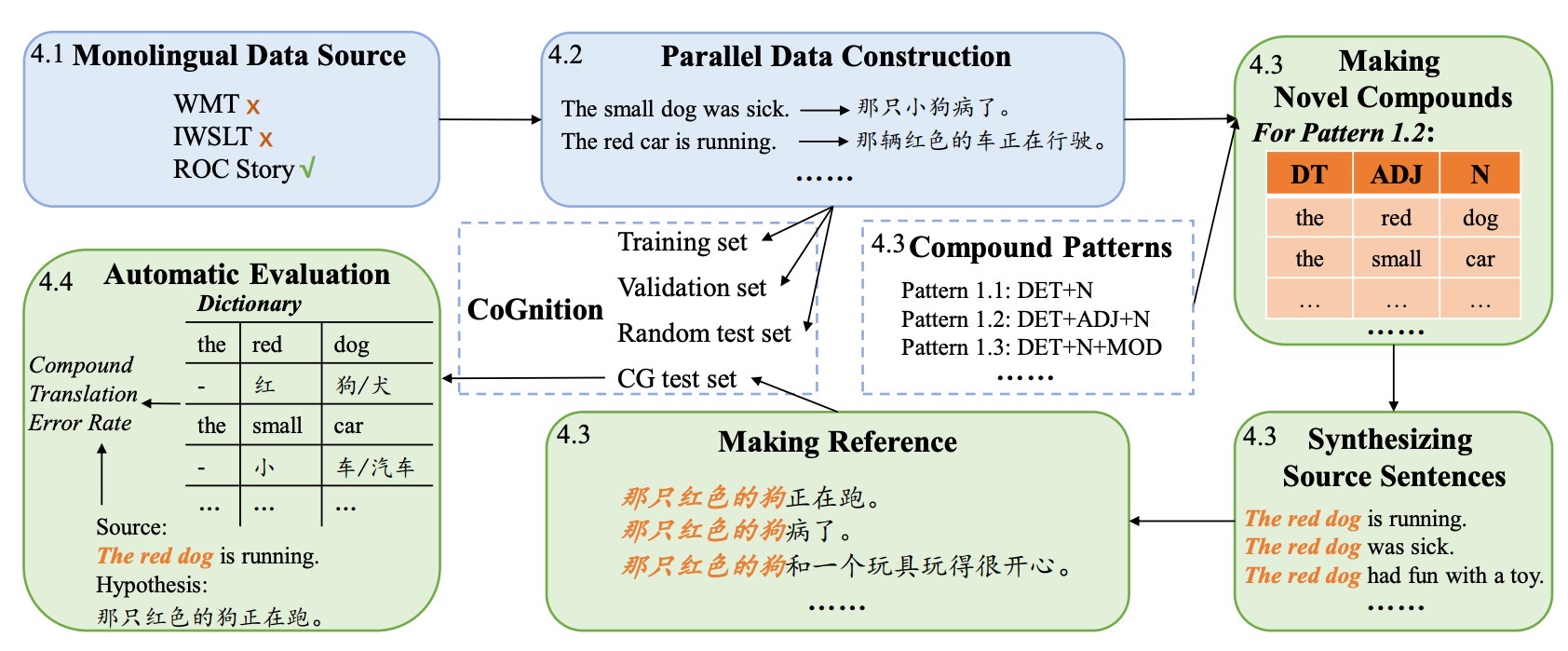
Haoran Zhang, Yafu Li†, Zhi Wang, Zhilin Wang, Shunkai Zhang, Xiaoye Qu, Yu Cheng preprint Github / Paper A framework for robust and scalable evaluation for complex reasoning. |
|
Tingchen Fu, Yafu Li†, Jiawei Gu, Xiaoye Qu, Yu Cheng preprint Github / Paper A tension between scaling up reasoning capacity and maintaining controllability. |
|
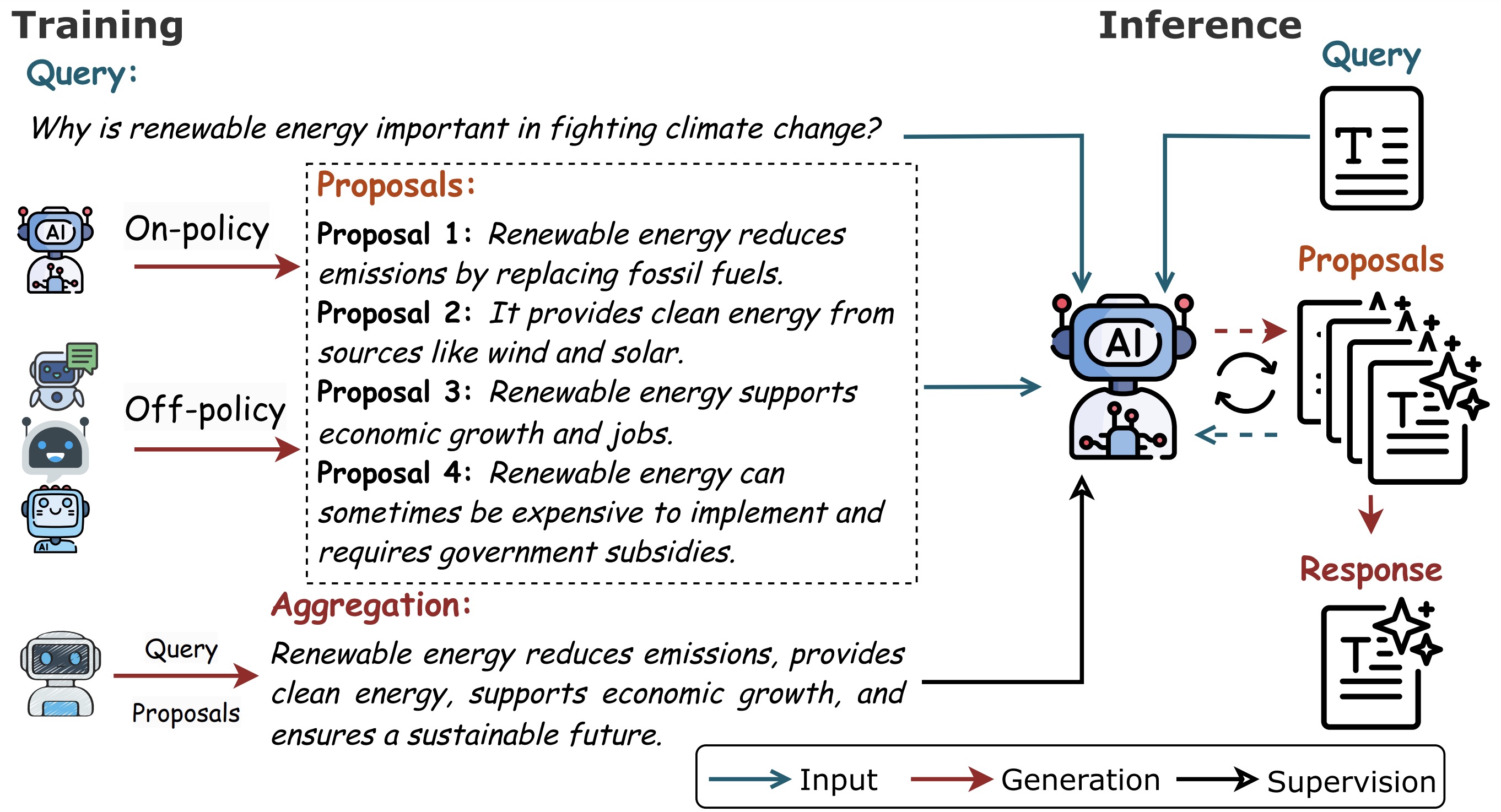
Yafu Li*, Zhilin Wang*, Tingchen Fu, Ganqu Cui, Sen Yang, Yu Cheng preprint Github / Paper Training models to aggregate multiple responses. |
|
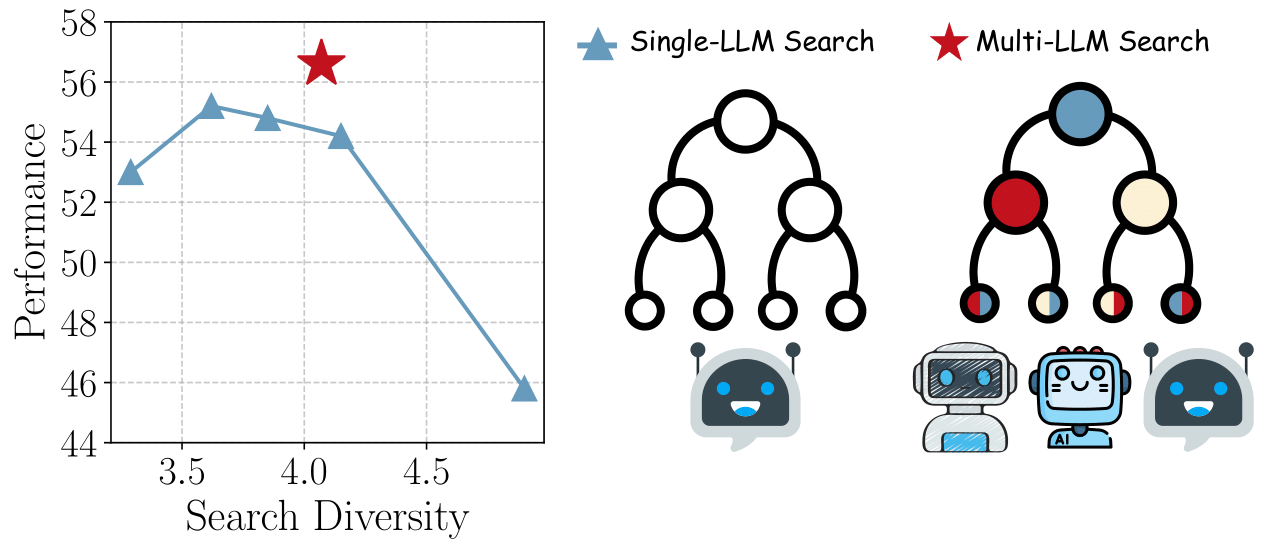
Sen Yang,Yafu Li†, Wai Lam, Yu Cheng preprint Paper Aggregate multiple agents for complex reasoning. |
|
|
|
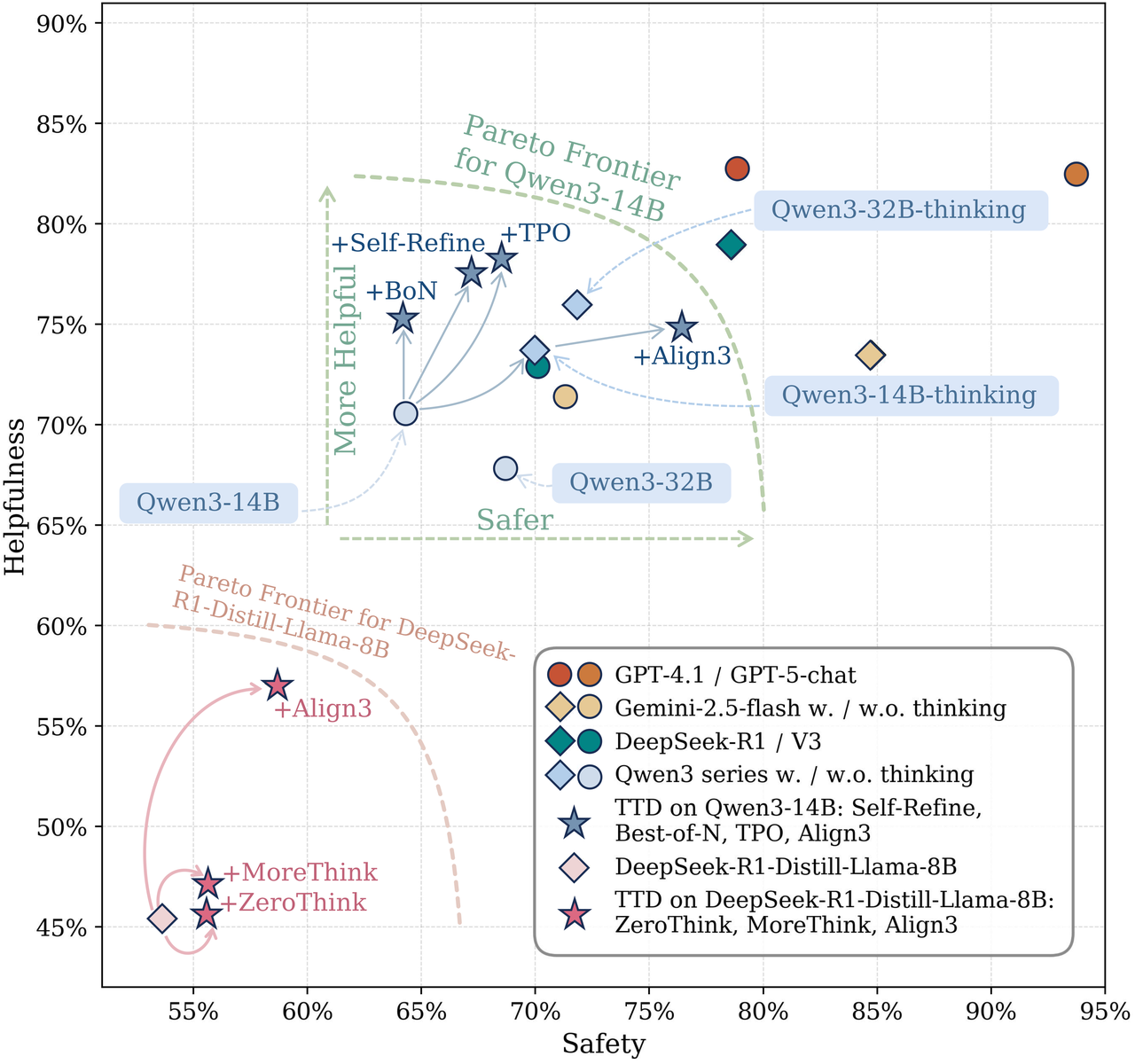
Haoran Zhang, Yafu Li†, Xuyang Hu, Dongrui Liu, Zhilin Wang, Bo Li, Yu Cheng preprint Github / Paper Reasoning over safety and behavourial boundaries before answering. |
|
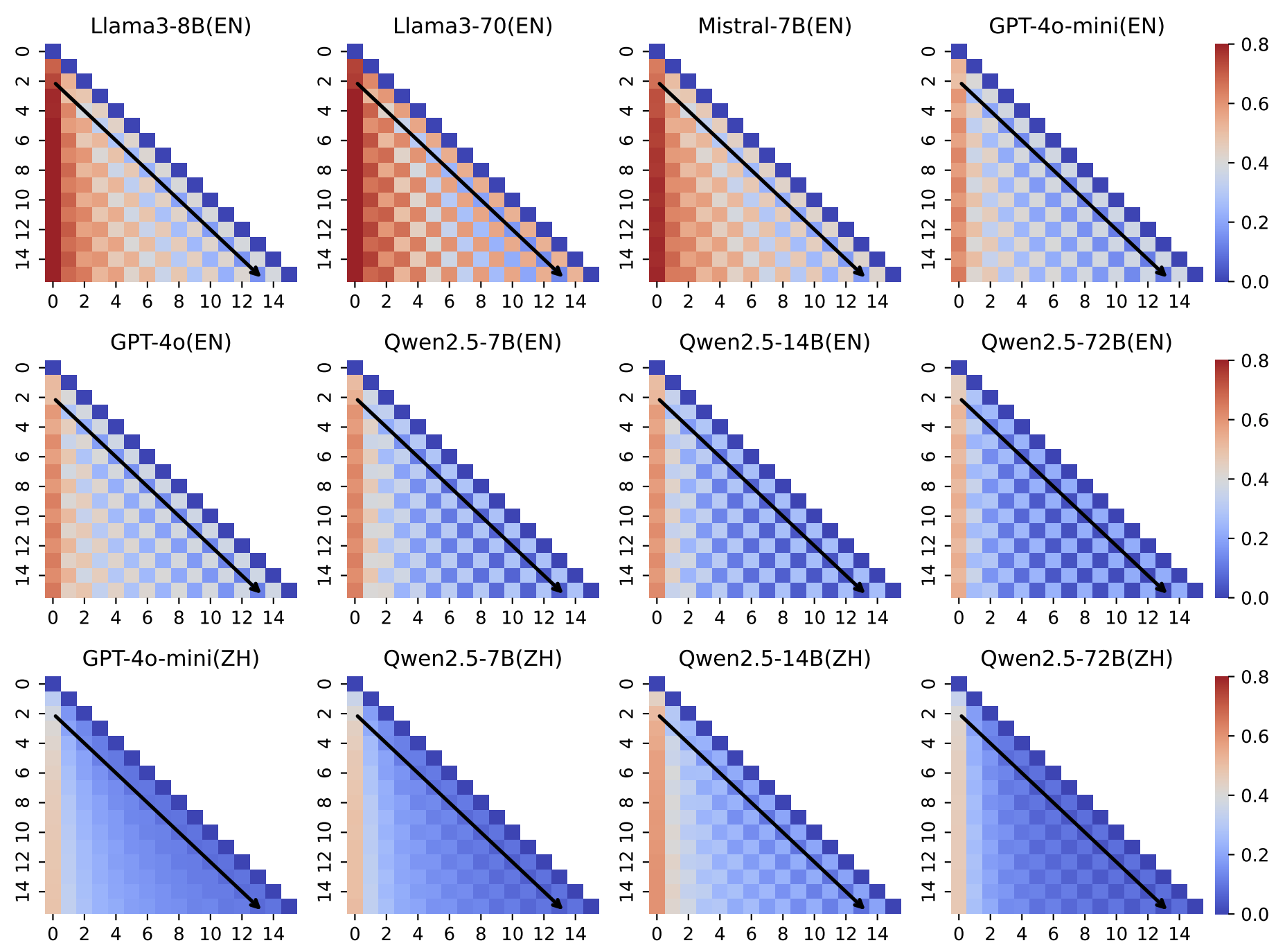
Zhilin Wang*, Yafu Li*†, Jianhao Yan, Yu Cheng, Yue Zhang ACL, 2025 Paper Unveiling attractor cycles in LLMs through dynamical systems analysis. |
|
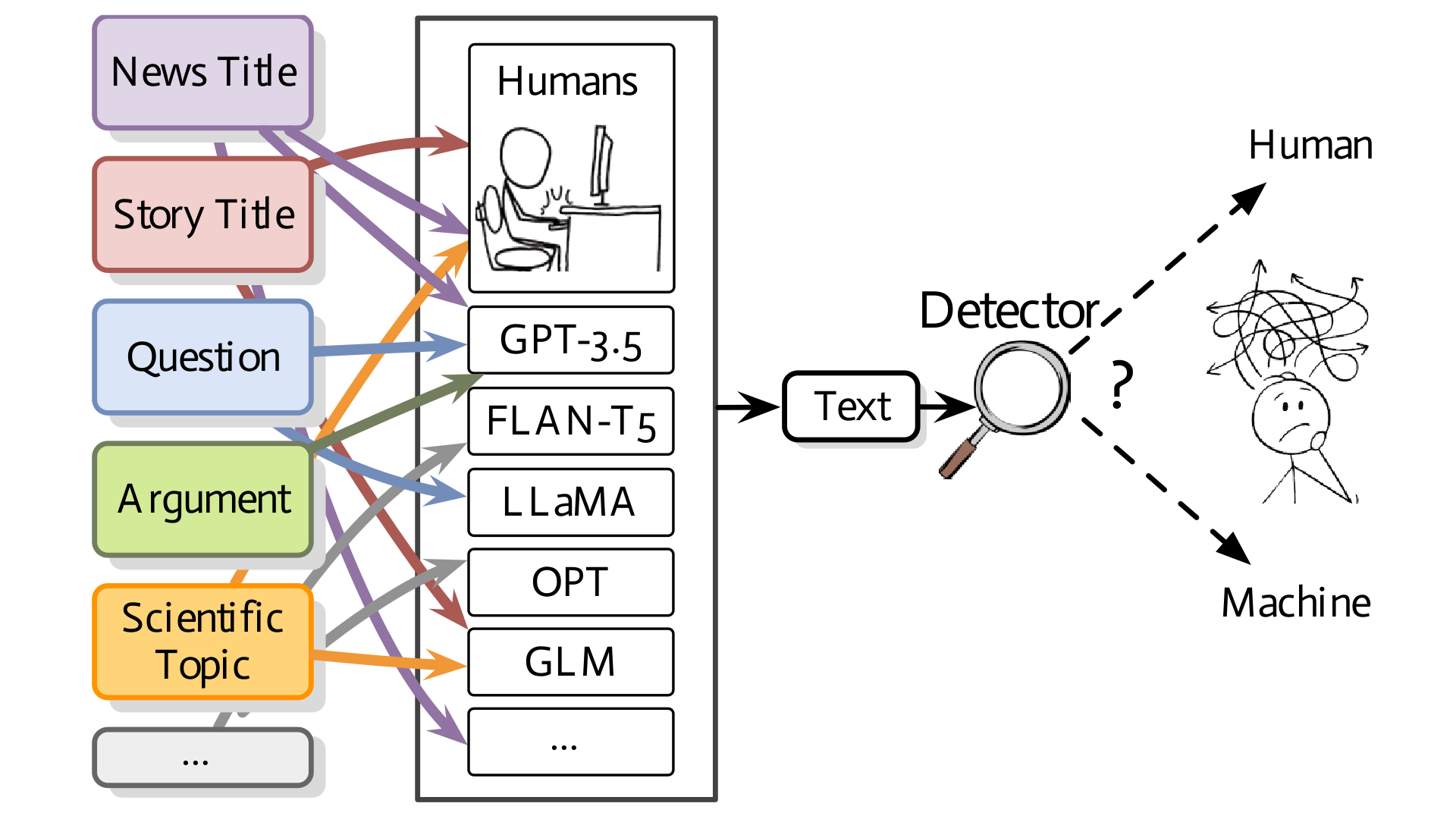
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang ACL, 2024 Github / Paper Assessing the proficiency of machine-generated text detectors amidst real-world scenarios. |
|
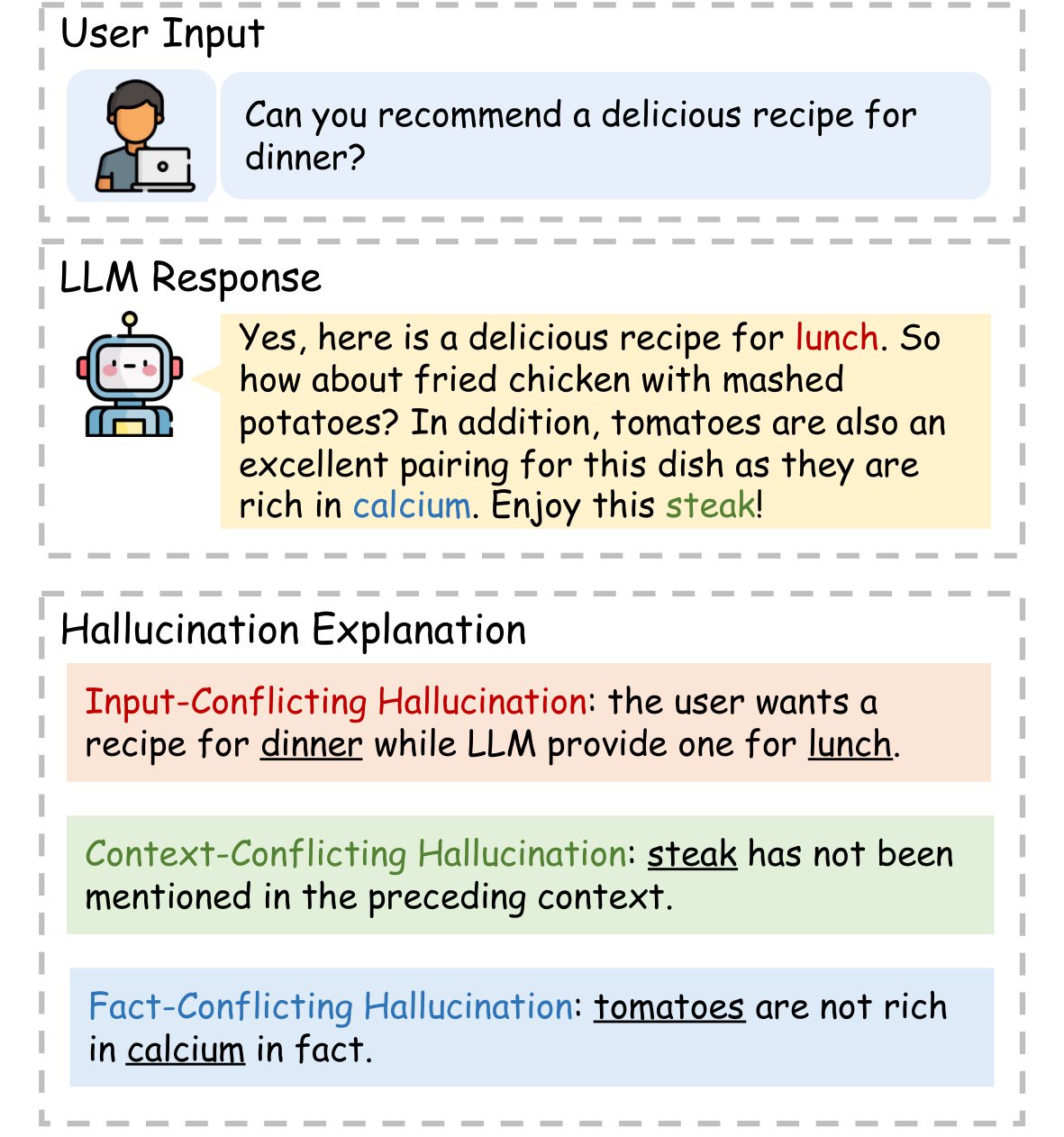
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, Shuming Shi Computational Linguistics Github / Paper A survey of hallucination in LLMs. |
|
|

|
Yafu Li*, Ronghao Zhang*, Zhilin Wang, Huajiang Zhang, Leyang Cui, Yongjing Yin, Tong Xiao, Yue Zhang ACL, 2025 Github / Paper A systematic study of the origin of translationese in LLMs and mitigation methods. |
|
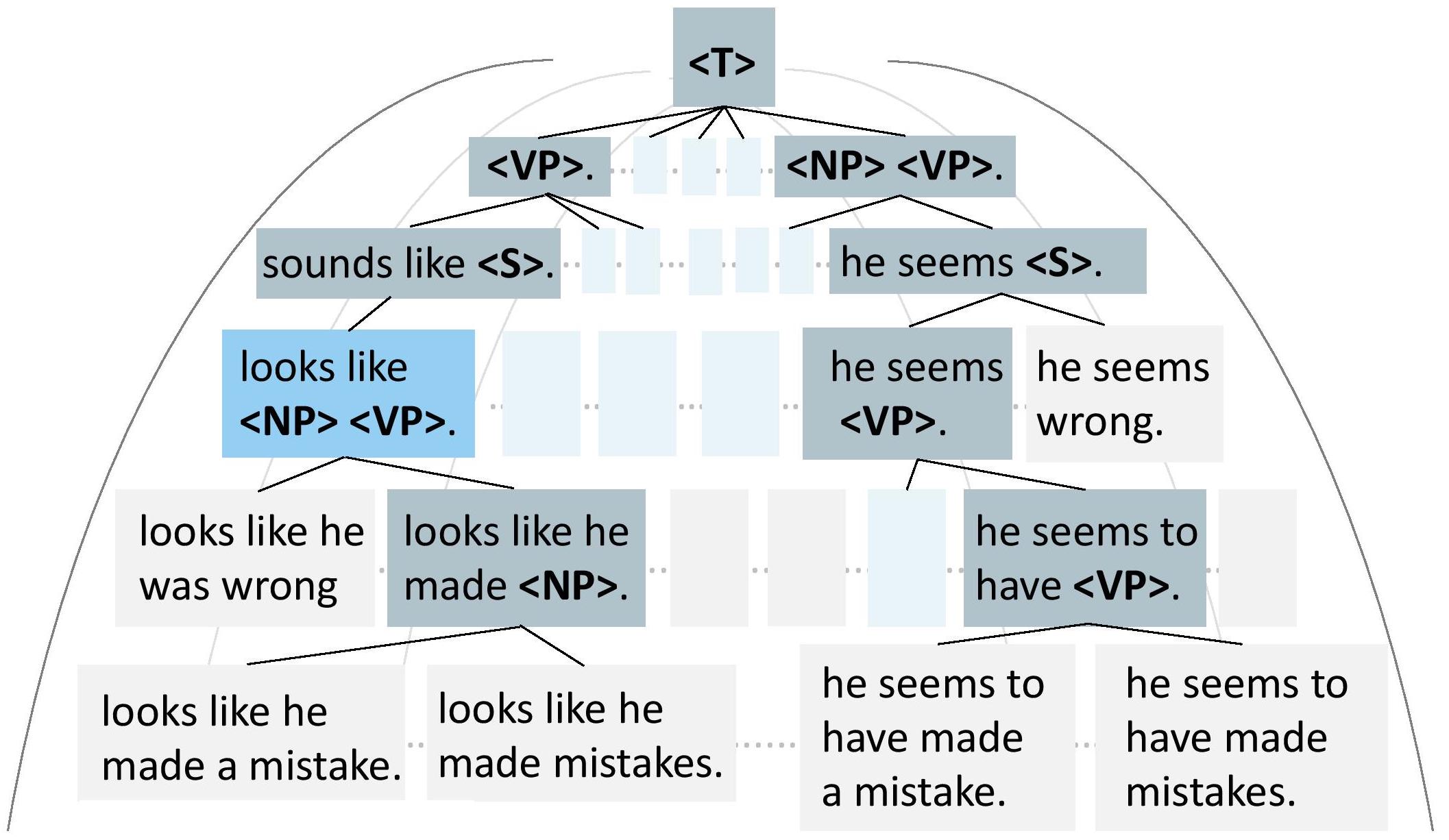
Yafu Li, Leyang Cui, Jianhao Yan, Yongjing Yin, Wei Bi, Shuming Shi, Yue Zhang ACL, 2023, Best Paper Nomination (1.6%) Github / Paper A neural symbolic method that guides generation with rules. |
|
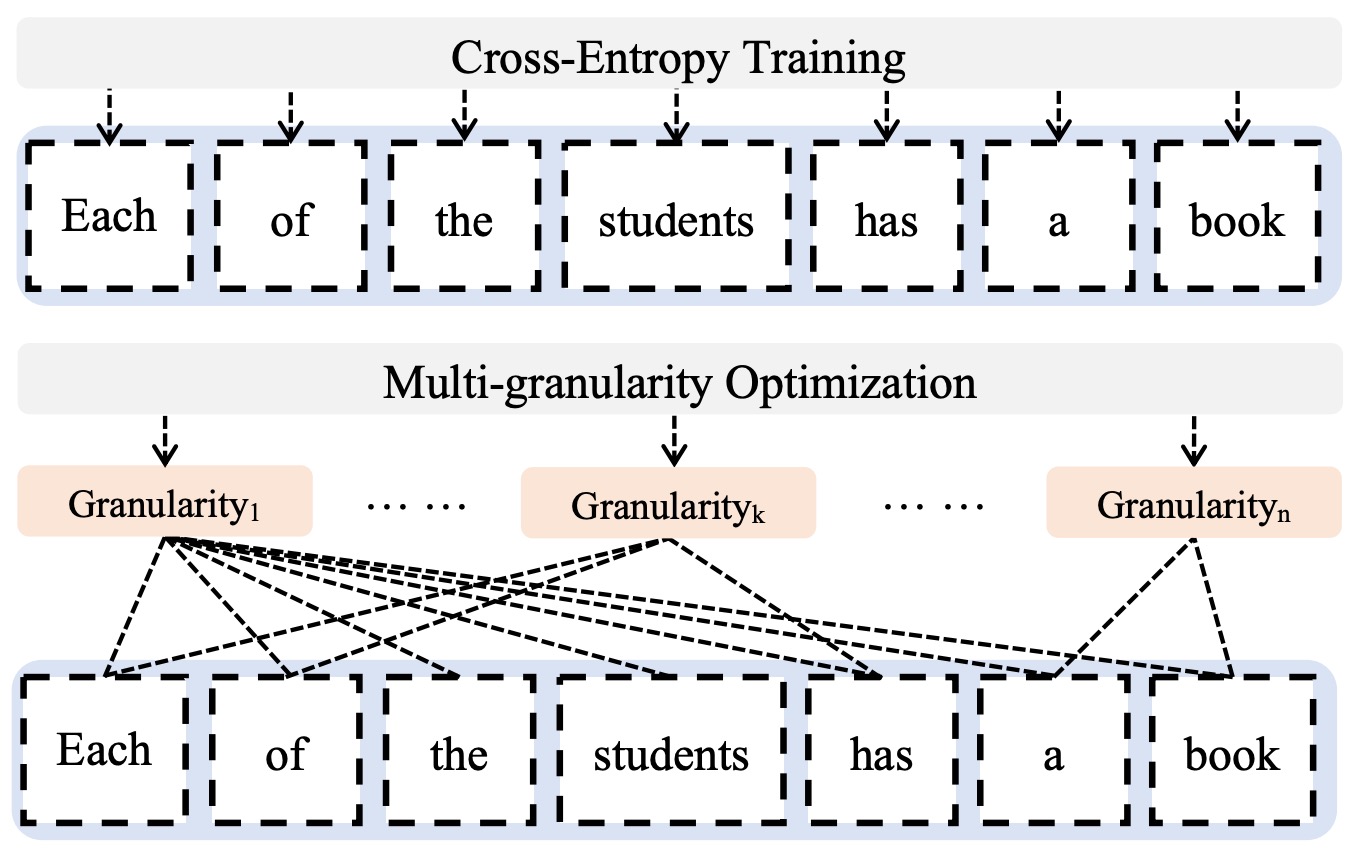
Yafu Li, Leyang Cui, Yongjing Yin, Yue Zhang EMNLP, 2022 Github / Paper Optimizing non-autoregressive translation with multi-granularity policy gradient. |
|
Yafu Li, Yongjing Yin, Yulong Chen, Yue Zhang ACL, 2021, Oral Github / Paper Neural machine translation suffers poor compositionality. |
|
I closely supervise and mentor research interns and students. Selected mentees and their representative publications include: Runzhe Zhan: ICLR 2026 Zican Hu: ICLR 2026 Shilin Zhang: ICLR 2026 Guanxu Chen: ICLR 2026 Yuxian Jiang: preprint Haoran Zhang: preprint Jianhao Yan: NeurIPS 2025 Tingchen Fu: preprint Sen Yang: preprint Ronghao Zhang: ACL 2025 Zhilin Wang: ACL 2024 Findings; ACL 2025; ACL 2025 Findings; Huajian Zhang: ACL 2024 Findings We are looking for full-time researchers, research interns and joint PhD students (with THU, PKU, SJTU, FDU, etc.) to work on cutting-edge research in large language models. |
|
October 27, 2025 — Invited lecture at Southern University of Science and Technology: On the Evolution of Reasoning Abilities in Large Language Models September 4, 2025 — Invited lecture at Tencent: Evolving Reasoning Abilities of LLMs: RLVR, Off-Policy Learning, and Test-Time Reinforcement Learning August 12, 2025 — Invited speaker at CCL 2025 Forum on Large Model Reasoning and Reinforcement Learning |
|
Area Chair: ACL 2025, EMNLP 2025 Conference Reviewer: ACL, EMNLP, COLING, ACL ARR, IJCAI, NeurIPS, ICLR. Journal Reviewer: TMLR, JAIR, TACL, TASLP, TBD, TALLIP. |
|
Outstanding Student Scholarship (Silver medal, Tencent Rhino-Bird Elite Program, 2024). National Scholarship (Ministry of Education, 2023). Dean's Medal (Westlake University, 2023). |
|
Website's code is from Jon Barron. |